
러스트 글을 몇개나 쓰다가 지웠는지 모르 겠는데 제발 제대로좀 써야겠다.
Hello World!
모든 언어의 시작은 Hello World!를 표준출력하는 것이니 해봅시다. cargo는 러스트의 패키지매니저이고 프로젝트를 만들면 헬로월드는 자동으로 만들어준다.
cargo new hello
요래 만들어지고 들어가서 실행해보면 다음과 같다.

cargo로 만들면 기본적으로 src/main.rs와 Cargo.toml이 생성된다. npm init과 유사하다. 실행하고 나면 여타 컴파일언어들과 비슷하게 뭐가 많이 생성된다.
다른걸 만들어 봅시다.
책에서 영어, 독일어, 한국어로 Hello World!를 만들고 있다. Grüß Gott!라니.. 시이카가 생각나네… 얘를 넣는 이유는 러스트가 기본으로 UTF-8을 사용하는 것을 보여주려고 하는 건데… 이게 요즘에 왜 필요한가 생각해보니 12년전에 C에서 일본 한자가 깨져서 개고생했던 옛날이 떠올랐다…
fn main() {
greet_world();
}
fn greet_world() {
println!("Hello, world!");
let southern_germany = "Grüß Gott!";
let korean = "안녕, 세상아!";
let regions = [southern_germany, korean];
for region in regions.iter() {
println!("{}", ®ion);
}
}- 함수 뒤에 오는 느낌표는 매크로라고 한다. 인라인같은건가?
- 러스트의 할당은 let 을 사용한다. javascript의 let과는 다르게 기본적으로는 재할당할 수 없다. let만으로 선언된 변수에 재할당을 하면 컴파일타임에 에러가 난다.
- 배열 리터럴은 여타 언어와 마찬가지로 대괄호를 사용한다.
- 컬렉션에는 iter()라는 이터레이터를 반환하는 메서드가 있다. 자바의 iterator()와 유사하고, 이 이터레이터를 이용해서 for 루프를 돌 수 있는 듯 하다.
- 변수 앞의 앰퍼샌드는 영역 내의 값을 읽기 전용으로 빌려올 때 사용한다고 한다. 근데 앰퍼샌드 없어도 잘 작동한다.
추가로 greet_world를 일부러 main 뒤에오도록 했는데 이래도 에러가 안난다. C/C++은 선언을 먼저 했어야 에러가 안났을텐데…
러스트의 특징
- 러스트는 객체지향이 아니지만 객체지향 언어의 메서드 관련 요소를 사용할 수 있다.
- 함수는 인자나 반환값으로 사용할 수 있다.
- 타입 어노테이션이라는 컴파일러에게 힌트를 제공하는 것이 있다고 한다.
- 조건부 컴파일이 가능하여 환경에 따라 로직을 포함하거나 제외할 수 있다. C/C++에서는 #ifdef 같은 전처리문으로 했던 짓이다.
- 러스트는 return 키워드가 있으나 보통 생략하고 마지막에 있는 것이 반환된다.
나는 언어를 배울때 내가 치지 않으면 마음이 안놓여서 책에 있는 코드를 좀 바꿔봅시다.
fn main() {
let data = "\
length, bread, ham, sauce
50, white, bacon, mustard
20, wheat, turkey, mayo
10, rye, ham, mustard
invalid, white, , ketchup
";
let records = data.lines();
for (i, record) in records.enumerate() {
if i == 0 || record.trim().is_empty() {
// 첫 줄이거나 공백인 경우
continue;
}
let fields = record
.split(",")
.map(|field| field.trim())
.collect::<Vec<_>>(); // Vec<_>는 벡터의 타입을 추론하라는 의미
if cfg!(debug_assertions) {
// debug 모드인 경우
eprintln!("debug: {:?} -> {:?}", record, fields);
}
let bread = fields[1];
let ham = fields[2];
let sauce = fields[3];
if let Ok(length) = fields[0].parse::<u32>() {
// fields[0]이 u32로 파싱 가능한 경우 let Ok(length)에서 length에 값을 할당하고 if문을 실행
println!(
"{:?} - {}cm, {} + {}, sauce: {}",
i, length, bread, ham, sauce
);
} else {
// fields[1]이 u32로 파싱 불가능한 경우
eprintln!("error: invalid length in record: {}", record)
}
}
}몇가지를 알아보면…
- 멀티라인텍스트는 “\ 로 시작하면 되는 듯 하다
- lines는 문자열을 개행으로 나눠준다
- enumerate는 index와 함께 iterate할 수 있도록 해준다.
- map은 그 map이다. 예시에서는 람다를 썼으나 str::trim으로도 잘 작동한다.
- cfg!(debug_assertions)로 싸인 부분은 디버그모드에서만 작동한다.
- if let Ok(_) 는 아직도 뭔지 모르겠는데… 문자열의 parse::<Type>() 메서드?가 Result라는걸 반환하는데 이게 성공하면 Ok, 에러가 발생했으면 Err을 반환한다. if let Ok(length)는 뒤의 결과가 성공했을 경우 그 값을 length에 할당하고 if 안쪽으로 넘어가며 뒤의 결과가 실패했을 경우 else를 실행한다.
- ::<u32>는 parse의 타입 어노테이션이다. 해당 스트링을 어떤 형식으로 파싱할지를 알려줘야하기 때문에 적어야한다.
그래서 그냥 실행시키면 (cargo run) 디버그 모드로 실행되어
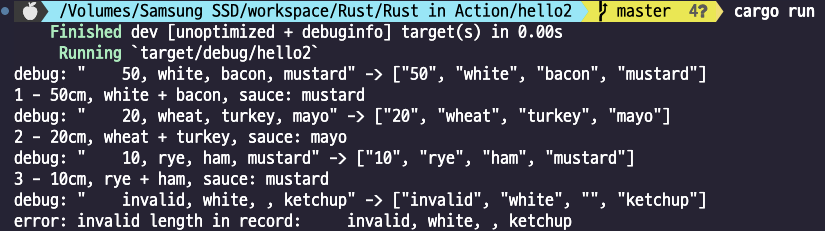
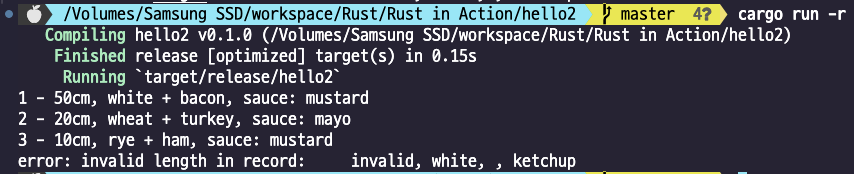
그래서 러스트는 다른 언어와 뭐가 다른가? 이런 문법적인 것 말고 책에 나와있기로는.. 치명적인 보안 버그의 7할은 잘못된 데이터 접근과 관련이 있다는 연구가 있고, 러스트는 이런 버그를 제거하여 메모리 안정성을 높인다고 한다.
C/C++의 경우에는 포인터를 이용하면 별의 별짓을다 할수 있어서 속도는 빠르고 메모리 할당등에 직접 개입할 수 있으나 그만큼 안정성이 떨어지고, 파이썬과같은 스크립트 언어들은 인터프리터가 예기치않은 동작을 막을 수 있으나 프로그래머가 메모리 할당 방식등을 세밀하게 제어할 수 없다. 근데 러스트는 다 된다고 자랑을 한다.
러스트의 안전성
러스트는 다음이 없다고 한다.
- 댕글링 포인터
실행 중 유효하지 않은 데이터 참조를 방지한다.
fn main() {
let mut v: Vec<u32> = vec![];
v.push(1); // v의 마지막에 1을 추가
drop(v); // v를 해제
println!("{:?}", v); // v를 사용하려고 하지만 이미 해제되었으므로 컴파일 에러 발생
}컴파일을 하면 Copy trait이 구현되지 않은 Vec<u32> 타입의 v를 move가 drop(v)에서 일어났으며 move가 일어난 다음 값을 borrow하려 했다면서 컴파일 에러가 난다.

시발 뭔소리야. 이건 나중에 나오겠지.
- 레이스 컨디션
레이스 컨디션으로 인한 문제가 생길만한 코드도 컴파일러가 잡아낸다. 같은 변수에 대해 서로 다른 스레드가 변경할 수 없도록 한다.
fn race_condition() {
let mut data = 100;
thread::spawn(|| { data = 500; });
thread::spawn(|| { data = 1000; });
println!("{}", data); // 100, 500, 1000 중 어느 값이 출력될지 모름
}이 역시 컴파일 타임에 에러가 난다. 에러를 발생시키지 않으려면 람다 앞에 move 키워드를 사용하라고 하는데, 이 경우 부모스레드의 data와 자식스레드의 data는 서로 다른 것이 된다.
- 오버플로
간단히 말하자면 크기가 고정된 리스트에서 인덱스에서 벗어난 곳을 참조하려고 하거나 반복 도중 변경이 일어나는 경우를 잡아낸다.
러스트의 통제력
생산성 뭐시기도 있는데 이건 그렇게 큰 내용이 아니다. 통제력은 아까 말한대로 러스트가 아무리 안전한 언어라고 해도 메모리 할당 방식과 같은 건 프로그래머가 지정할 수 있다는 말인것 같다. 근데 자세히 보니 이것도 어쨌든 C++에서 비스무리한걸 본거 같은데;;; 기본적으로 참조 횟수를 셀 수 있도록 하는 std::rc::Rc나 mutex로 접근하도록 atomic 참조 카운터를 이용하는 std::sync::Arc, std::sync::Mutex등이 있다고 한다.
그리고 챕터1의 내용은 러스트가 어디에 쓰이고 뭐가 강점이고 뭐 주저리주저리… 거기에 러스트가 모든 에러를 막을 수는 없으니 생각좀 하고 코딩하라고 써있다..
후… 다음에는 드디어 뭔가를 만드려고 하나봄.
끗
답글 남기기